Tema 38: analítica predictiva II
PETER B. MANDEVILLE
CIENCIA UANL / AÑO 18, No. 72, MARZO-ABRIL 2015
An approximate answer to the right problem is worth a good deal more than an exact answer to an approximate problem.
John W. Tukey
Un ejemplo de medicina:
Las epidemias de la influenza de temporada constituyen un importante problema de salud pública que causa decenas de millones de enfermedades respiratorias y de 250,000 a 500,000 muertes en el mundo cada año. (1)
Además de la influenza estacional, una nueva cepa del virus de la influenza contra el cual no existe inmunidad previa, y que demuestra transmisión de humano a humano, podría dar lugar a una pandemia con millones de víctimas mortales. (1)
La detección temprana de la actividad de la enfermedad, si la sigue una respuesta rápida, puede reducir el impacto tanto de la influenza estacional como de la pandemia. (1)
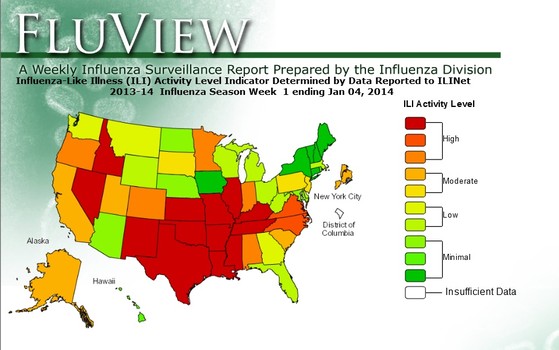
La vigilancia tradicional se basa en la recopilación de numerosos indicadores que incluyen los síntomas clínicos, los resultados de laboratorio de virología, ingresos hospitalarios, las estadísticas de mortalidad, (2) el número de visitas a los hospitales, los síntomas de los pacientes, los tratamientos de los pacientes, el seguimiento de las visitas a la sala de emergencia, la realización de pruebas de laboratorio y encuestas de la población, (3) a fin de determinar cuántas visitas de pacientes están relacionadas con la influenza en las nueve regiones de los EUA. Los Centers for Disease Control and Prevention (CDC) utilizan sistemas tradicionales de vigilancia con un retraso de información de una a dos semanas. (4)
En 2009 se descubrió un nuevo virus, H1N1, con elementos de los virus de la influenza aviar y la influenza porcina. Agencias de salud pública en todo el mundo temían que una pandemia estuviera en marcha. No existía una vacuna contra el nuevo virus. La única esperanza para frenar su propagación que tenían las autoridades era la localización de las respectivas zonas donde se encontraba presente el virus.
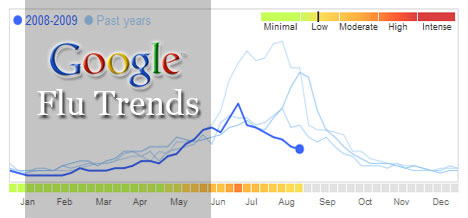
Unas semanas antes de que H1N1 fuera noticia, ingenieros de Google Flu Trend (GFT) publicaron un artículo en la revista Nature, explicando cómo GFT podría ‘predecir’ la propagación de la influenza de invierno en los EUA, no sólo a nivel nacional, sino en regiones específicas incluyendo los estados. Fue logrado mediante el análisis de los patrones de búsqueda. Google recibe más de 3 mil millones de búsquedas todos los días y todos son almacenados. (5)
Se realizaron cerca de 50 millones de búsquedas semanalmente dentro de los EUA de 2003 a 2008. Se calculó una serie de tiempo de cada una para cada estado que fue normalizado al dividir el número de cada búsqueda por el número total de las búsquedas en el estado. Se puede determinar el estado en que fue introducida una búsqueda al identificar la dirección IP asociada. Entonces se utilizó un modelo lineal para calcular el log-odds de la visita al médico con Illness Like Influenza (ILI) y el log-odds de la búsqueda. (3-6)
Fue probada cada una de las 50 millones de búsquedas a determinar si el resultado calculado a partir de una sola búsqueda coincide con los datos de ILI de los CDC. El resultado de este proceso fue una lista de las búsquedas que son las mejores predictoras de ILI. (3-6)
Se formuló un modelo lineal con las 45 búsquedas más importantes como las variables explicativas. Se ajustó el modelo a los datos semanales de ILI entre 2003 y 2007. Por último, se utilizó este modelo de entrenamiento para predecir los brotes de influenza en las regiones de los EUA. (3-6)
Este algoritmo ha sido revisado posteriormente por GFT como respuesta a la preocupación por la precisión. Intentos de replicar los resultados han sugerido que los desarrolladores del algoritmo “sentían una necesidad no articulada para encubrir los términos de búsqueda”. (3-6)
Un estudio publicado en la Royal Society Open Science demuestra que se pueden utilizar los datos de búsqueda de GFT para mejorar significativamente las estimaciones del número de casos de la influenza. Tam- bién reduce los errores de utilizar los datos de los CDC en hasta un 52.7%. (6)
En la pandemia de influenza de 2009, GFT rastreó información sobre la influenza en los EUA. En febrero de 2010, los CDC identificaron un pico de casos de influenza en la región del Atlántico de los EUA. Sin embargo, el análisis de GFT fue capaz de mostrar ese mismo pico dos semanas antes del informe de los CDC. (6)
El documento inicial (1) declaró que las predicciones del GFT fueron de un exactitud de 97% comparadas con las de los CDC. Sin embargo, los informes posteriores afirmaron que hay ocasiones en que las predicciones GFT han sido muy imprecisas, sobre todo durante el intervalo de 2011 a 2013 cuando se sobreestimo consistentemente la prevalencia de la influenza. (6)
Un análisis concluyó que “mediante la combinación de GFT y los datos de los CDC puede calibrar las predicciones dinámicamente y puede mejorar sustancialmente el rendimiento”. (6)
Mappy Health escanea datos en tiempo real de Twitter, y busca las tendencias de salud a través de la búsqueda de 234 términos. Se presenta la información recopilada en gráficos con la finalidad de ayudar a los usuarios a notar las tendencias que se reportan con más rapidez que los métodos tradicionales.3
Sickweather escanea millones de mensajes de Facebook y tweets en Twitter para 24 síntomas de la influenza, posteriormente efectúa un análisis lingüístico para eliminar la información no relacionada con la influenza y entonces se grafican los resultados en un mapa.3
No se basa GFT en una pequeña muestra aleatoria, sino que se utilizan todas las miles de millones de búsquedas de Internet en los EUA. El uso de todos estos datos en lugar de una muestra pequeña mejora el nivel de predicción del análisis de la propagación de la influenza hasta una ciudad en lugar de un estado o la nación.5
En lugar de obsesionarse con la precisión, la exactitud, la limpieza y el rigor de los datos, se puede dejar un poco de holgura. No se deben aceptar datos que son erróneos o falsos, pero un poco de desorden puede ser aceptable a cambio de un conjunto más completo de datos. De hecho, en algunos casos puede llegar a ser beneficioso, ya que cuando se intenta utilizar sólo una pequeña parte exacta de los datos, ésta puede no captar la amplitud de detalle.5
Debido a que se pueden calcular las correlaciones mucho más rápido que la causalidad, a menudo éstas son preferibles. Todavía harían falta los estudios causales y experimentos controlados con variables cui- dadosamente seleccionadas en casos específicos. Para muchas necesidades cotidianas, el saber el “que” y no el “porque” es más que suficiente. A su vez, las correlaciones de datos grandes pueden señalar áreas prometedoras para la exploración de relaciones causales. (5)
Para mayor información sobre analítica predictiva, las citas 7-10 son textos con ejemplos de varias disci- plinas. La cita 11 tiene ejemplos de la medicina y la cita 12 tiene ejemplos de comercio.
También, se recomienda el curso Statistical Learning que es gratuito en Stanford Online y ense- ñado por Trevor Hastie y Rob Tibshirani con un Promotional Video en:
https://www.youtube.com/watch?v=St2-97n7atk y la Course Page en https://class.stanford.edu/courses/HumanitiesandScience/StatLearning/Winter2015/ about con fecha de inicialización el 20 de enero 2015 finalizando el 05 de abril 2015.
Referencias
- Ginsberg J., Mohebbi M.H., Patel R.S., Brammer L., Smolinski M.S., Brilliant L. (2009). Detecting influen- za epidemics using search engine query data, http:// cs.wellesley.edu/~cs315/Papers/ Predicting%20flu%20epidemics.pdf
- Dugas A.F., Jalalpour M., Gel Y., Levin S., Torcaso F., Igusa T., Rothman R.E. (2013). Influenza Forecasting with Google Flu Trends, http:// www.ncbi.nlm.nih.gov/pmc/articles/PMC3572967/ pdf/pone.0056176.pdf
- Konkel F. (2013). Predictive analytics allows feds to track outbreaks in real time, http://fcw.com/articles/ 2013/01/25/flu-social-media.aspx
- Bari A., Chaouchi M., Jung T. (2014). Predictive Analytics for Dummies. John Wiley & Sons, Inc., New York, NY, USA.
- Mayer-Schonberger V., Kukier K. (2014). Big Data. Houghton Mifflin Harcourt Publishing Company, New York, NY, USA.
- Google Flu Trends. (2014, November 1). In Wikipedia, The Free Encyclopedia. Retrieved 23:25, February 20, 2015, from http://en.wikipedia.org/w/ index.php?title=Google_Flu_Trends&oldid=631999740
- Hastie T., Tibshirani R., Friedman J. (2009). The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed., Springer Science+Business Media, LLC, New York, NY, USA.
- James G., Witten D., Hastie T., Tibshirani R. (2013). An Introduction to Statistical Learning with Applications in R. Springer Science+Business Media, LLC, New York, NY, USA.
- Kuhn M., Johnson K. (2013). Applied Predictive Modeling. Springer Science+Business Media, LLC, New York, NY, USA.
- LantzB.(2013).MachineLearningwithR:Learnhow to use R to apply powerful machine learning methods and gain an insight into real-world applications. Packt Publishing, Birmingham, UK.
- Steyerberg E.W. (2009). Clinical Prediction Models: A Practical Approach to Development, Validation, and Updating. Springer Science+Business Media, LLC, New York, NY, USA.
- Ohri A. (2012). R for Business Analytics. Springer Science+Business Media, LLC, New York, NY, USA.